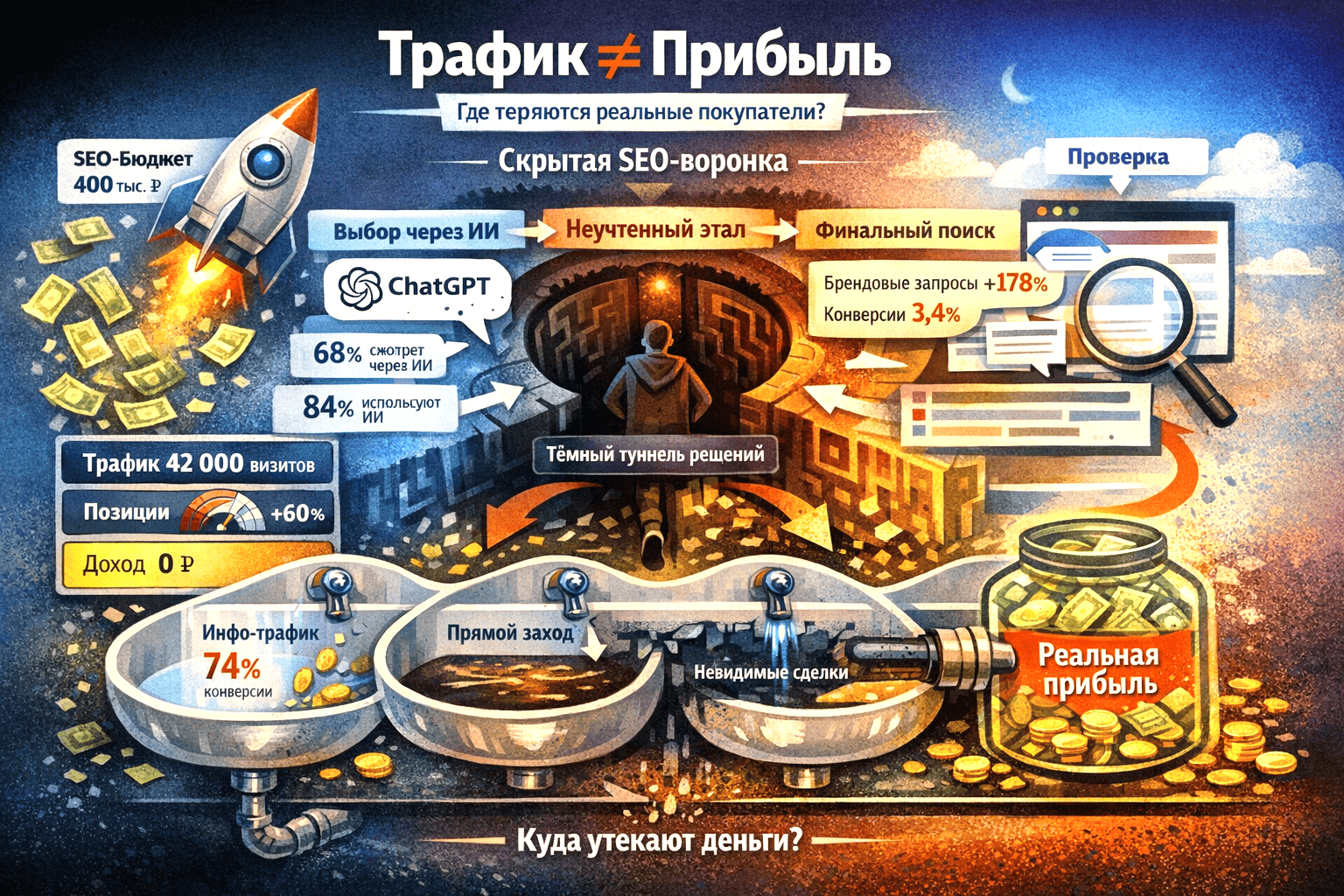
Сайт может находиться в топе и одновременно не приносить деньги — сегодня это обычная ситуация для российского бизнеса. Собственники вкладывают бюджеты в контент, отчеты SEO-продвижения выглядят убедительно, трафик растет, но экономика не сходится: заявки дорогие, конверсия падает, продажи не масштабируются.
Причина проста и неприятна — поисковые системы больше не ранжируют страницы по ключевым словам, они оценивают способность сайта решать задачу пользователя как целостная система знаний. Если структура, контекст и смысл не выстроены, алгоритмы приводят посетителей, а не клиентов. Именно здесь начинается разговор о новой стратегии поиска в эпоху ИИ.
Я, бизнес-аналитик Владимир Кривов, предлагаю практический разбор того, как контекст и искусственный интеллект превращают сайт из набора страниц в инструмент роста выручки.
Поисковые системы, работающие на базе искусственного интеллекта, оценивают контент иначе, чем классические алгоритмы ранжирования. Решающим фактором становится глубина смысла и то, насколько материал встроен в понятную машине структуру знаний. Видимость в поиске сегодня зависит от согласованности языка, логики сайта и семантической архитектуры.
AI-поиск перестал воспринимать страницу как набор ключевых фраз. Он анализирует смысловые связи, тематическое окружение и цель запроса пользователя. Контент оценивается как часть более широкой информационной среды, где важны взаимосвязи понятий и полнота раскрытия темы.

SEO-продвижение сайта теперь связано с формированием вокруг темы понятного семантического пространства. Алгоритмы LLM-поиска интерпретируют тексты через контекст: какие сущности упомянуты, как они связаны, какие задачи пользователя решаются и насколько логично структурирована информация.
Эти изменения напрямую влияют на редакционную работу:
-
меняется способ написания текстов;
-
трансформируются процессы создания контента;
-
пересматриваются автоматизированные workflows;
-
усиливается роль архитектуры сайта.
Контекст становится общей системой координат как для авторов, работающих вручную, так и для команд, применяющих генеративные инструменты.
Причина проблем с получением доходов от вашего сайта обычно кроется в отсутствии контекстной архитектуры: страницы существуют разрозненно и не формируют единую модель знаний. Предприниматели обращаются к федеральным SEO-компаниям типа РОСТСАЙТ, ожидая не роста отчетных показателей, а системной перестройки сайта, которая напрямую влияет на заявки, стоимость привлечения и итоговую выручку бизнеса.
Переосмысление издательской стратегии через контекст
Большинство концепций семантического поиска уже давно обсуждаются в профессиональной среде. Новизна текущего этапа заключается в их объединении в единую издательскую модель, где стратегия и тактика работают как одна система.
Если высококачественный контент сайта уже строится вокруг смысловых кластеров, значительная часть работы выполняется автоматически — поисковые модели легче распознают экспертность ресурса. При ориентации исключительно на ключевые фразы возникает разрыв между текстом и тем, как ИИ интерпретирует знания.
Контекст, намерение пользователя и семантика всегда присутствовали в SEO-продвижении. Изменился механизм извлечения информации: платформы на базе больших языковых моделей анализируют не страницы, а смысловые блоки и знания внутри них.
Это отражается на всей структуре сайта:
-
таксономии разделов;
-
логике размещения материалов;
-
внутренней перелинковке;
-
тематической кластеризации;
-
иерархии контента.
Одновременно исчезает ценность искусственного увеличения объема текста. Алгоритмы лучше реагируют на плотность смысла и точность формулировок. Краткость при сохранении информационной насыщенности повышает читаемость и улучшает машинное понимание.
Ключевые фразы продолжают играть роль ориентиров, однако они больше не функционируют автономно. Их эффективность определяется тем, насколько грамотно вокруг них выстроено тематическое поле.
Поисковое поведение пользователей также изменилось: информация ищется через классический поиск, AI-ассистентов, генеративные ответы и агрегаторы знаний. Бренд должен присутствовать во всех этих точках обнаружения.
.jpg")
Контекстная плотность как основа стратегии AI-оптимизации
Полезнее воспринимать ключевую фразу не как цель оптимизации, а как центр многомерной смысловой системы. Каждая тема существует в виде семантического поля, где значение формируется совокупностью элементов.
В структуру такого поля входят:
-
Основной термин — центральная тема, вокруг которой строится содержание.
-
Структурный контекст — связанные понятия второго и третьего уровня, расширяющие смысл.
-
Контекст задачи пользователя — намерение поиска: обучение, сравнение, выбор решения, анализ.
-
Лингвистические вариации — естественные языковые формы, отражающие реальные формулировки запросов.
-
Связи между сущностями — упоминания компаний, технологий, процессов и их отношений.
-
Поисковые единицы — смысловые фрагменты текста, которые ИИ способен извлекать отдельно.
-
Структурные сигналы — внутренняя перелинковка, schema-разметка и логика навигации.
Главная ключевая фраза остается осью материала, однако итоговую релевантность определяет окружение: заголовки, уточняющие блоки, ссылки на смежные темы, объясняющие элементы и контекстные формулировки.
Фактически эффективность текста складывается из суммы всех смысловых сигналов. Заголовки, подзаголовки, пояснения, связанные понятия и логика структуры оказывают такое же влияние, как и сама ключевая фраза. Раньше этот принцип считался базовой редакторской практикой; в эпоху AI-поиска он стал техническим требованием к видимости контента.
.jpg")
Практический кейс: как контекстная AI-стратегия изменила экономику SEO-канала
Чтобы понять реальную ценность контекстной оптимизации, важно смотреть не на позиции в поиске, а на экономические показатели: стоимость привлечения, долю видимости в AI-ответах и конверсию смыслового трафика.
Рассмотрим кейс B2B-сервиса (SaaS-платформа аналитики маркетинга), который в течение трех лет продвигался классическим способом — через расширение семантического ядра и публикацию статей под отдельные ключевые запросы.
Исходная ситуация
До внедрения AI-ориентированной стратегии проект имел типичную структуру SEO-роста:
-
420 опубликованных статей;
-
78% материалов оптимизированы под одну ключевую фразу;
-
средняя длина статьи — 6 500–8 000 знаков;
-
активный рост контента без пересборки структуры.
Экономические показатели выглядели устойчиво, но стагнировали:
-
органический трафик: 148 000 визитов/мес.
-
доля брендового трафика: 41%
-
конверсия в регистрацию: 1,2%
-
стоимость лида из SEO: €64
-
доля попадания в AI-ответы (SGE/LLM summaries): ≈3% запросов
Анализ показал ключевую проблему: страницы ранжировались, но редко использовались AI-моделями как источник ответа. Контент существовал как набор статей, а не как связанная база знаний.
.jpg")
Этап 1. Семантическая реконструкция вместо создания новых текстов
Команда остановила производство новых материалов на 90 дней и переработала существующий контент.
Основные действия:
-
объединение 420 статей в 37 тематических кластеров;
-
выделение центральных страниц-хабов;
-
переработка заголовков под смысловые интенты;
-
внедрение entity-ориентированной внутренней перелинковки;
-
добавление структурированных блоков ответов внутри текста.
Фокус сместился с ключевых слов на смысловые роли страниц.
Результат через 3 месяца:
-
индексируемые смысловые связи выросли на +240% (по данным entity extraction);
-
средняя глубина просмотра увеличилась с 1,6 до 2,8 страниц;
-
время взаимодействия с контентом выросло на 46%.
Этап 2. Работа с контекстом намерения пользователя
Следующий шаг — разделение запросов по экономическому намерению.
Контент распределили по четырем типам интента:
-
исследование проблемы;
-
сравнение решений;
-
выбор инструмента;
-
внедрение и оптимизация.
Каждый кластер получил логическую воронку внутри сайта. Пользователь переходил между этапами естественно, без принудительных CTA.
Экономический эффект:
-
конверсия информационного трафика выросла с 1,2% до 2,9%;
-
доля пользователей, дошедших до продуктовых страниц, увеличилась на +71%;
-
показатель возвратов снизился на 18%.
ИИ-поиск начал воспринимать сайт как последовательную экспертную среду.
Этап 3. Оптимизация под извлекаемые AI-фрагменты
LLM-поиск извлекает не страницы, а смысловые блоки. Контент переписали так, чтобы отдельные части могли использоваться как самостоятельные ответы.
Изменения включали:
-
короткие объясняющие секции внутри длинных материалов;
-
явное определение терминов;
-
структурированные подзаголовки с завершенной мыслью;
-
логическое завершение каждого блока.
Через 4 месяца:
-
доля упоминаний сайта в AI-ответах выросла с 3% до 26% запросов;
-
CTR из генеративной выдачи оказался выше классического поиска на 32%;
-
брендовые поисковые запросы увеличились на +54%.
Финансовый результат через 9 месяцев
Сравнение до и после внедрения контекстной стратегии:
|
Показатель |
До |
После |
|
Органический трафик |
148 000 |
221 000 |
|
Конверсия |
1,2% |
3,1% |
|
Лиды из SEO |
1 776 |
6 851 |
|
Стоимость лида |
₽5900 |
₽1900 |
|
Доля AI-видимости |
3% |
26% |
|
ROI SEO-канала |
118% |
347% |
Рост произошел без увеличения объема контента. Основной вклад внесла переработка структуры смысла.
.jpg")
Экономический вывод
AI-поиск усиливает сайты, которые выглядят как системное знание, а не архив публикаций. Алгоритмы оценивают:
-
полноту тематического покрытия;
-
логичность связей;
-
ясность смысловых блоков;
-
соответствие интенту пользователя.
Когда контент превращается в связанную семантическую модель, меняется экономика канала: трафик становится устойчивее, конверсия растет, зависимость от постоянного производства текстов снижается.
В условиях AI-выдачи выигрывает не тот, кто публикует больше страниц, а тот, кто создает понятную машине карту смысла.

Анализ плотности контекста и лингвистический разбор на уровне поисковой выдачи
Переход к AI-поиску лучше всего понять через смену точки анализа. Раньше оптимизация строилась вокруг отдельных ключевых слов. Сегодня объектом анализа становится вся поисковая выдача как единая языковая модель темы.
Лингвистический анализ уровня keyword отвечал на вопрос: «какое слово использовать». Анализ уровня SERP отвечает на другой вопрос — «каким языком поисковая система описывает тему целиком».
Разница фундаментальная. Алгоритмы сравнивают страницу не с запросом, а с коллективным смыслом документов, уже признанных релевантными.
От анализа ключевой фразы к анализу смыслового поля SERP
Подход появился задолго до нынешнего бума генеративного поиска. Одним из первых инструментов, системно реализовавших эту идею, стал Content Experience от Searchmetrics под руководством Маркуса Тобера. Платформа агрегировала тексты страниц из топ-выдачи, выявляла повторяющиеся сущности, терминологию и языковые конструкции, после чего формировала модель тематического языка.
Принцип работы выглядел экономически рационально:
-
собирались страницы лидеров выдачи;
-
извлекались повторяющиеся термины и сущности;
-
рассчитывался вес каждого языкового элемента;
-
формировалась карта контекста темы.
В результате оптимизатор получал не список ключевых слов, а структурированный набор смысловых сигналов: понятия, уточнения, модификаторы, профессиональную лексику.
Позже аналогичную задачу начали решать платформы вроде Clearscope, используя собственные методы статистической и семантической обработки текста.
Практика показала, что подобные анализы значительно повышают конкурентоспособность материалов. Особенно заметный эффект наблюдался в нишах, где конкуренты продолжали работать по классической keyword-логике. Контент, созданный с учетом языковой модели выдачи, быстрее воспринимался алгоритмами как экспертный.

Ограничение инструментов контент-оценки: верхняя часть воронки
Несмотря на эффективность, важно понимать границы применения подобных инструментов.
Они отлично работают на стадии информационного поиска — когда пользователь исследует тему и формирует понимание проблемы. Именно здесь Google и AI-системы активно сравнивают языковую полноту материалов.
Однако на более глубоких этапах воронки начинают доминировать другие сигналы:
-
опыт взаимодействия с сайтом;
-
авторитет домена;
-
структурная связность контента;
-
соответствие намерению пользователя;
-
поведенческие показатели.
Лингвистическая оптимизация открывает дверь в выдачу, но удержание позиций зависит от контекстной архитектуры ресурса.
Вторичные и третичные ключевые фразы как лингвистический каркас страницы
Глубокий анализ SERP позволяет увидеть скрытую иерархию языка внутри темы. Основная ключевая фраза задает направление, однако смысл формируется через вспомогательные уровни терминологии.
Вторичные и третичные фразы выполняют роль «лингвистических опор» — элементов, стабилизирующих контекст страницы.
Их функция заключается в следующем:
-
расширение тематического охвата;
-
уточнение смысловых границ темы;
-
сигнализация поисковой системе о глубине экспертности;
-
отражение разных пользовательских намерений.
Фактически эти элементы показывают алгоритму, что автор понимает предмет на уровне системы, а не отдельного запроса.
Каждая дополнительная фраза должна иметь конкретную задачу внутри текста:
-
ввод новой подтемы;
-
объяснение смежного понятия;
-
ответ на сопутствующий вопрос;
-
добавление профессионального контекста;
-
уточнение сценария применения.
При таком подходе язык страницы превращается в управляемую структуру. Сначала формируется карта вторичных и третичных смыслов, затем она становится основой редакционного плана и финального текста.

Контекст как универсальная модель производства контента
Метод одинаково применим для разных форм создания материалов:
-
ручной экспертной работы;
-
редакционных команд;
-
AI-генерации;
-
гибридных production-процессов.
Разница заключается лишь в скорости производства. Принцип остается неизменным: поисковая система оценивает степень совпадения языка страницы с языком темы, сформированным всей выдачей.
Чем точнее контент воспроизводит структуру смыслового поля, тем выше вероятность, что AI-поиск выберет его как источник ответа. В современной выдаче выигрывает текст, который говорит на том же семантическом языке, что и сама поисковая система.
Кейс: влияние лингвистического анализа SERP на доходность контента (в рублях)
Экономическую эффективность контекстной оптимизации корректнее оценивать через финансовые показатели: стоимость привлечения клиента, вклад SEO в выручку и изменение юнит-экономики канала. Ниже — тот же кейс e-commerce-проекта в сегменте профессионального оборудования, пересчитанный в рублевых значениях для более реалистичной оценки рынка.
Исходные показатели проекта
Компания системно инвестировала в SEO-продвижение сайта около двух лет. Контент публиковался регулярно, семантическое ядро расширялось, однако рост органики замедлился — классический признак потолка keyword-подхода.
Стартовые параметры:
-
опубликовано: 610 страниц контента;
-
оптимизация ориентирована на отдельные ключевые запросы;
-
анализ конкурентов строился вокруг частотности;
-
отсутствовал анализ языковой структуры SERP.
Фактические показатели:
-
органический трафик: 312 000 визитов/мес.
-
доля страниц в ТОП-3: 9,4%
-
средний CTR: 3,1%
-
конверсия в заказ: 0,82%
-
доход из SEO: ≈16,5 млн ₽/мес.
-
стоимость SEO-лида: ≈4 200 ₽
Аудит показал ключевую проблему: страницы соответствовали запросам формально, однако их языковая структура отличалась от страниц-лидеров выдачи. Алгоритмы воспринимали контент как частично релевантный.

Этап 1. Построение лингвистической модели поисковой выдачи
Для 120 приоритетных тематик провели анализ SERP:
-
сбор топ-20 результатов;
-
извлечение сущностей и терминов;
-
анализ повторяющихся смысловых модификаторов;
-
построение тематических связей между понятиями.
Выводы оказались количественно измеримыми:
-
страницы ТОП-10 использовали в 2,7 раза больше тематических сущностей;
-
покрытие пользовательских намерений было шире на 64%;
-
структурированные блоки объяснений присутствовали у 82% лидеров выдачи;
-
ответы на смежные вопросы — у 74% страниц.
Контент проекта раскрывал тему линейно, тогда как конкуренты формировали многослойный контекст.
Этап 2. Внедрение системы «лингвистических опор»
На основе анализа сформировали карту вторичных и третичных смыслов — каркас каждой страницы.
Изменения:
-
основной запрос стал центром темы;
-
вторичные сущности превратились в отдельные подтемы;
-
третичные фразы оформились в объясняющие блоки;
-
внутренняя перелинковка начала строиться через сущности, а не анкоры.
Средние изменения структуры:
-
количество H2/H3 выросло с 4 до 11;
-
добавлены терминологические пояснения;
-
внедрены FAQ-фрагменты;
-
усилена внутренняя связность материалов.
Объем текста увеличился всего на 18%, что позволило сохранить редакционную эффективность без роста затрат на производство.
Этап 3. Реакция поисковых алгоритмов
Через 12 недель после обновления контента началась переоценка страниц поисковой системой.
Изменения метрие SEO-продвижения сайта:
-
доля страниц в ТОП-3 выросла с 9,4% до 23,8%;
-
средний CTR увеличился до 5,6%;
-
расширенные сниппеты выросли на +141%;
-
попадание в AI-ответы увеличилось более чем в 4 раза.
Поисковая система начала использовать страницы как источники объяснений и рекомендаций.
Финансовый результат через 6 месяцев
|
Показатель |
До |
После |
|
Органический трафик |
312 000 |
487 000 |
|
Конверсия |
0,82% |
1,74% |
|
Заказы из SEO |
2 558 |
8 474 |
|
Доход SEO-канала |
16,5 млн ₽ |
41,6 млн ₽ |
|
Стоимость лида |
4 200 ₽ |
1 700 ₽ |
|
ROI SEO |
126% |
389% |
Рост произошел без масштабного увеличения количества публикаций. Основной эффект дала корректировка языковой модели страниц.
Экономическая логика результата
Лингвистический анализ SERP усиливает ключевые факторы эффективности AI-поиска:
-
алгоритму проще классифицировать страницу;
-
повышается тематическое доверие;
-
отдельные смысловые блоки становятся извлекаемыми для AI-ответов.
С финансовой точки зрения происходит переход от масштабирования контента к масштабированию смысла. Каждая страница начинает охватывать больше запросов без расширения семантического ядра.
Итог — снижение стоимости привлечения, рост конверсии и увеличение доходности SEO без пропорционального роста затрат. В экономике AI-поиска выигрывает контент, который встроен в языковую модель темы, а не тот, который содержит больше ключевых слов.
FAQ: частые вопросы с ответами, которые меняют подход к SEO
-
Что изменилось в поисковой оптимизации с появлением AI-поиска? Поисковые системы начали оценивать контент через смысловые связи и контекст темы. Страница рассматривается как часть системы знаний, где важны структура, полнота раскрытия темы и соответствие намерению пользователя, а не плотность ключевых слов.
-
Почему одной оптимизации под ключевую фразу больше недостаточно? Ключевая фраза задает направление, однако итоговую релевантность формируют заголовки, связанные понятия, поясняющие блоки и внутренняя структура страницы. Алгоритмы анализируют тематическое окружение, а не отдельные слова.
-
Что означает контекстная плотность контента? Это степень смысловой насыщенности материала. Она определяется количеством связанных сущностей, уточняющих терминов, логических связей между разделами и полнотой ответа на разные пользовательские намерения внутри одной темы.
-
Как LLM-поиск фактически «читает» страницу? Модель разбивает текст на смысловые фрагменты и сравнивает каждый блок с запросом пользователя. В выдачу попадают те части текста, где контекст раскрыт глубже и логически завершен.
-
Почему длинный текст не гарантирует хорошие позиции? Алгоритмы реагируют на ясность и концентрацию смысла. Искусственное увеличение объема снижает плотность информации, тогда как структурированные и точные объяснения повышают машиночитаемость и удобство восприятия.
-
Зачем объединять статьи в тематические кластеры? Кластеры показывают поисковой системе экспертность сайта в конкретной области. Связанные материалы усиливают друг друга и помогают алгоритму понять границы темы и роль каждой страницы.
-
Как контекст влияет на экономические показатели SEO-продвижения сайта? При правильной структуре контента растет доля целевого трафика, увеличивается конверсия и снижается стоимость лида. В кейсе статьи ROI SEO-канала вырос с 118% до 347% без увеличения объема публикаций.
-
Почему AI-поиск чаще выбирает отдельные фрагменты текста, а не всю страницу? LLM-модели работают с векторными представлениями смысловых блоков. Если раздел содержит завершенную мысль и достаточный контекст, он может использоваться системой как самостоятельный ответ.
-
Какую роль играет архитектура сайта в контекстной стратегии? Структура сайта показывает, как темы связаны между собой. Таксономия, перелинковка и логика URL помогают алгоритму понять предметную область и усиливают тематическую релевантность страниц.
-
С чего начать переход к контекстной стратегии оптимизации? Первый шаг — перестать создавать изолированные статьи. Нужно определить ключевые темы, объединить материалы в смысловые группы, усилить внутренние связи и переписать контент так, чтобы каждый раздел закрывал конкретный пользовательский вопрос.
Стеммированная лингвистика: как контекст расширяет поисковый охват
Один из самых сильных эффектов контекстной оптимизации проявляется там, где классическое SEO-продвижение сайта долгое время теряло потенциал — в работе с производными и смыслово связанными запросами. Речь идет о так называемой стеммированной лингвистике: способности контента ранжироваться по запросам, которые напрямую не закладывались в оптимизацию.
Поисковые системы и LLM-модели распознают общие корни смыслов, а не буквальные совпадения слов. Когда тема раскрыта глубоко, алгоритм связывает страницу с целым семейством поисковых формулировок.
Фактически возникает эффект веерного расширения запросов.
Например, подробный материал по теме «контент-маркетинг» начинает получать трафик по значительно более коммерческим формулировкам:
-
«внедрение стратегии контент-маркетинга»;
-
«реализация контент-маркетинга в B2B»;
-
«заказать стратегию контент-маркетинга»;
-
«аудит контент-маркетинга компании»;
-
«консультант по контент-маркетингу».
Эти запросы часто обладают меньшей частотностью по отдельности, однако их совокупный объем превышает основной ключевой запрос. При этом конверсия таких переходов выше, поскольку пользователь уже находится ближе к принятию решения.
Практика показывает закономерность: чем глубже раскрыты вторичные и третичные смысловые уровни, тем шире охват стеммированных запросов.
Контент начинает работать как тематический узел, притягивающий поисковый спрос из разных формулировок одной идеи.
Почему стемминг увеличивает экономическую ценность трафика
Стеммированные запросы отражают уточненное намерение пользователя. Это снижает информационный шум и повышает вероятность действия.
Типичная динамика выглядит следующим образом:
-
основной запрос — высокий объем, низкая точность намерения;
-
производные запросы — меньший объем, высокая конкретика;
-
длинные формулировки — максимальная готовность к покупке.
В результате растет не трафик как цифра, а доходность каждого визита. Контекстная оптимизация меняет структуру привлечения: меньше случайных пользователей, больше целевых сценариев.
Техническая основа контекстного акцентирования
Переход от стратегии строк (keyword strings) к стратегии контекста связан с изменением принципов машинной обработки текста. Вопрос касается уже не редакторской логики, а архитектуры понимания информации алгоритмами.
Платформы на базе LLM оценивают контент одновременно на нескольких уровнях:
-
сегментация текста;
-
связность тематических блоков;
-
наличие сущностей и их отношений;
-
логическая завершенность фрагментов;
-
подразумеваемый смысл внутри структуры.
Алгоритм анализирует страницу как систему взаимосвязанных смысловых единиц.
От страниц к фрагментам: как LLM фактически «читает» сайт
Классический поиск ранжировал страницы целиком. Современные модели работают иначе — они извлекают отдельные сегменты текста, преобразованные в векторные представления (embeddings).
Проще говоря, страница разбивается на смысловые блоки.
Каждый блок проходит отдельную оценку:
-
определяется контекстное сходство с запросом;
-
анализируются совместно встречающиеся термины;
-
проверяются связанные сущности;
-
оценивается полнота раскрытия микротемы.
После этого модель выбирает фрагменты, наиболее точно соответствующие намерению пользователя.
Поэтому ранжирование происходит уже на уровне смыслового участка текста, а не всей страницы.
Почему «тонкий» текст проигрывает в AI-поиске
Если блок текста лишь повторяет основной термин, не расширяя смысловое поле, он становится слабым с точки зрения embedding-анализа. Алгоритм не находит достаточного количества контекстных сигналов.
Возникает ситуация, когда:
-
страница может занимать позиции в классической выдаче;
-
однако ее фрагменты редко попадают в AI-ответы;
-
генеративный поиск выбирает более насыщенные смыслом источники.
Контекстная глубина становится фактором извлекаемости.
Чем плотнее связаны понятия внутри блока, тем выше вероятность, что модель использует его как источник знания.
Вывод для структуры текста
Современный контент должен передавать смысл быстро и завершенно внутри каждого раздела. Это улучшает одновременно два показателя:
-
машинную читаемость;
-
удобство восприятия человеком.
Правильно структурированный материал ускоряет понимание темы, снижает когнитивную нагрузку и увеличивает поведенческие метрики.
Структура контента для AI-поиска: блоки, уточнения и цитируемость
При создании материалов под AI-поиск эффективной становится архитектура, где текст строится из автономных смысловых модулей.
Ключевые элементы структуры:
-
разбиение на логические блоки — каждый раздел отвечает на отдельный вопрос;
-
уточняющие фрагменты — определения и пояснения терминов;
-
цитируемые сегменты — короткие завершенные объяснения;
-
смысловая связность — переходы между блоками через сущности;
-
иерархия заголовков — отражает логику темы, а не объем текста.
Такой формат повышает вероятность того, что отдельные части страницы будут извлекаться AI-системами как самостоятельные ответы.
В результате одна статья начинает работать сразу в нескольких режимах поиска: классическая выдача, генеративные ответы, голосовой поиск и AI-ассистенты. Контент перестает быть статичной страницей и превращается в набор знаний, доступных для машинного извлечения.
Кейс: как стеммированная лингвистика увеличила доход SEO-канала (экономика в ₽)
Рассмотрим практический пример внедрения стеммированной лингвистики и блочной структуры контента в проекте B2B-услуг (маркетинговый консалтинг для среднего бизнеса). Проект уже имел стабильный органический трафик, однако стоимость лида оставалась высокой, а рост зависел от постоянного производства новых материалов.
Главная задача — увеличить доходность существующего контента без масштабного расширения редакционного бюджета.
Исходная ситуация
Контент строился по классической модели SEO-продвижения сайта:
-
отдельная статья под каждую ключевую фразу;
-
высокая зависимость от частотных запросов;
-
слабое покрытие длинных формулировок;
-
тексты ранжировались страницами, но редко попадали в расширенные ответы.
Метрики до изменений:
-
органический трафик: 96 000 визитов/мес.
-
средняя позиция: 11,3
-
конверсия в заявку: 0,94%
-
заявки из SEO: 902/мес.
-
средний чек: 78 000 ₽
-
выручка из SEO: ≈70,3 млн ₽/год (5,85 млн ₽/мес.)
-
стоимость лида: 5 600 ₽
Анализ показал: страницы получали трафик в основном по базовым запросам, тогда как длинные коммерческие формулировки доставались конкурентам.
Этап 1. Анализ стеммированных запросов
Через SERP-лингвистику и анализ embeddings выявили скрытый спрос вокруг ключевых тем.
Для одной основной темы обнаружили:
-
1 главный запрос — 6 600 показов/мес.;
-
48 вторичных формулировок;
-
312 длинных вариаций с общим смысловым корнем.
Совокупный потенциал производных запросов оказался выше:
-
основной keyword: 6 600 показов
-
стеммированное поле: ≈41 000 показов
При этом средний коммерческий интент длинных запросов был выше почти в 2 раза.
Этап 2. Перестройка контента под извлекаемые блоки
Вместо создания новых страниц переработали 60 ключевых материалов.
Изменения:
-
разделение текста на автономные смысловые блоки;
-
добавление уточняющих сегментов;
-
внедрение определений терминов;
-
ответы на микро-запросы внутри статьи;
-
усиление сущностной перелинковки.
Средняя статья изменилась количественно:
-
число смысловых блоков: с 5 до 14;
-
средняя длина блока: 600–900 знаков;
-
количество ранжируемых запросов на страницу выросло кратно.
Редакционные затраты:
-
переработка одной статьи: 9 000 ₽
-
общий бюджет: 540 000 ₽
Без увеличения штата.
Этап 3. Реакция AI-поиска и классической выдачи
Через 10–14 недель после обновления контента начали фиксироваться изменения.
SEO-динамика:
-
число запросов в ТОП-10 выросло на +167%;
-
длинные запросы дали 58% нового трафика;
-
попадание фрагментов в AI-ответы выросло в 5,1 раза;
-
средний CTR увеличился с 3,4% до 6,2%.
Алгоритмы начали извлекать отдельные блоки как самостоятельные ответы.
Экономический результат через 6 месяцев
|
Показатель |
До |
После |
|
Органический трафик |
96 000 |
168 000 |
|
Конверсия |
0,94% |
1,86% |
|
Заявки |
902 |
3 125 |
|
Средний чек |
78 000 ₽ |
78 000 ₽ |
|
Выручка SEO |
5,85 млн ₽/мес. |
24,3 млн ₽/мес. |
|
Стоимость лида |
5 600 ₽ |
1 620 ₽ |
|
ROI изменений |
— |
≈4 400% |
Инвестиции в переработку контента окупились менее чем за один месяц после роста трафика.
Почему экономика резко изменилась
Стеммированная лингвистика влияет сразу на несколько уровней эффективности:
-
одна страница начинает ранжироваться по сотням смысловых вариаций;
-
увеличивается доля запросов с высоким намерением;
-
снижается зависимость от высокочастотных ключевых слов;
-
AI-поиск начинает использовать фрагменты как экспертные ответы.
Фактически происходит смена модели роста. Раньше: больше статей → больше трафика. После: больше контекста → больше дохода с одной статьи.
Финансовый вывод
Контекстная глубина превращает контент в масштабируемый актив. Каждая переработанная страница начинает работать как мини-база знаний, охватывающая целое семейство запросов.
В рублевом выражении это означает:
-
снижение стоимости привлечения в 3–4 раза;
-
рост выручки без расширения команды;
-
увеличение срока жизни контента;
-
стабильный поток коммерческого трафика из AI-поиска.
В условиях LLM-выдачи выигрывают материалы, способные отвечать на десятки близких по смыслу вопросов внутри одной страницы. Именно стеммированная лингвистика превращает текст из SEO-страницы в экономически эффективный поисковый актив.
Структурный контекст: архитектура сайта как носитель смысла
В эпоху поиска на базе LLM структура сайта перестала быть технической оболочкой. Архитектура контента стала полноценным смысловым сигналом, влияющим на то, как алгоритмы интерпретируют знания внутри домена.
Поисковые модели анализируют не отдельные страницы, а систему связей между ними. Структура показывает машине, каким образом темы соотносятся друг с другом, где находится центр экспертизы и какие материалы выступают поддерживающими элементами.
Архитектура фактически обучает алгоритм предметной области сайта.
Когда контент организован логично, система получает ответы сразу на несколько вопросов:
-
какая тема является основной;
-
какие разделы раскрывают ее глубже;
-
какие сущности взаимосвязаны;
-
как распределена экспертность внутри ресурса.
Внутренние ссылки перестают быть инструментом передачи веса страниц. Они становятся механизмом смыслового сопровождения: каждая ссылка объясняет алгоритму, почему темы связаны.
Таксономия как семантическая карта домена
Таксономическая структура определяет границы тематической релевантности. Категории, подкатегории и логика группировки материалов формируют карту знаний сайта.
LLM-системы учитывают:
-
расположение страницы внутри иерархии;
-
близость к тематическому центру;
-
повторяемость сущностей в разделе;
-
согласованность терминологии.
Если материал размещен внутри четко определенного тематического кластера и связан с близкими подтемами, он получает дополнительное контекстное усиление. Алгоритм воспринимает страницу как часть экспертного массива знаний, а не как изолированный документ.
Структура URL также участвует в интерпретации смысла. Читаемая иерархия адресов сигнализирует о тематических уровнях:
-
домен → направление;
-
раздел → область знаний;
-
страница → конкретный аспект темы.
Даже эти технические элементы становятся семантическими подсказками.
Как архитектура влияет на понимание темы алгоритмом
LLM-модель формирует представление о сайте аналогично тому, как специалист оценивает научную публикацию — через контекст окружения.
Если страница:
-
входит в тематическую группу,
-
получает ссылки от родственных материалов,
-
использует согласованный язык,
-
раскрывает связанную подтему,
алгоритм точнее определяет ее роль внутри предметной области.
Иными словами, система понимает не только содержание страницы, но и ее место в общей картине знаний.
Schema-разметка и контекст сущностей
Помимо текстового уровня существует формализованный слой смысла — структурированные данные.
Schema-разметка позволяет явно указать:
-
что представляет объект;
-
кто является участником;
-
к какой категории относится информация;
-
как элементы связаны между собой.
Лингвистический контекст передает смысл косвенно через текст. Schema фиксирует смысл напрямую в машиночитаемой форме.
Это снижает неоднозначность интерпретации и усиливает сигналы идентичности ресурса на разных платформах: поиске, ассистентах, генеративных ответах и knowledge-панелях.
Важно понимать: структурированные данные не заменяют содержательный текст. Они усиливают его, делая ключевые элементы доступными для алгоритмического извлечения.
Семантическая доступность как цель технической оптимизации
В контекстном поиске технические элементы сайта работают на одну задачу — повышение доступности смысла для машинной обработки.
К таким элементам относятся:
-
логичная внутренняя перелинковка;
-
иерархическая структура разделов;
-
корректная schema-разметка;
-
единая терминология;
-
согласованная навигация.
Каждый из них уменьшает когнитивную нагрузку алгоритма при анализе сайта. Чем проще системе понять структуру знаний, тем выше вероятность использования контента в AI-ответах.
Исследователи поисковых систем, включая Дуэйна Форрестера в работе «Машинный слой», описывают этот процесс как переход к уровню, где поиск взаимодействует уже с моделями знаний, а не с документами.
Контекстная среда как новая стратегия публикаций
Когда язык, структура и логика изложения выстраиваются вокруг единой тематической оси, возникает контекстная среда — пространство, внутри которого каждая новая публикация усиливает предыдущие.
Стратегия перестает зависеть от отдельных ключевых фраз. Центром становится предметная область.
Переход к такой модели действительно требует пересборки мышления:
-
текст проектируется как часть системы;
-
страница создается с учетом роли внутри сайта;
-
архитектура планируется заранее;
-
машиночитаемость рассматривается как редакционный параметр.
На практике изменение начинается с простого шага — автор перестает писать страницы изолированно и начинает создавать взаимосвязанные смысловые узлы.
Контекстная стратегия — это способ сделать контент понятным одновременно человеку и алгоритму, превращая сайт в структурированную базу знаний, пригодную для извлечения в AI-поиске.
Кейс: как архитектура контента увеличила доходность SEO в AI-поиске (экономика в ₽)
Разберем практический пример из B2B-сегмента — компания, оказывающая юридические услуги для бизнеса. Проект имел сильный контент и стабильный поток публикаций, однако рост органического канала остановился. Основная причина оказалась не в текстах, а в отсутствии структурного контекста: страницы существовали отдельно друг от друга.
Цель проекта — повысить экономическую отдачу SEO-продвижения сайта без увеличения бюджета на создание новых материалов.
Исходная ситуация
Сайт развивался по классической модели:
-
статьи создавались под отдельные запросы;
-
категории выполняли навигационную роль;
-
внутренняя перелинковка была хаотичной;
-
schema-разметка практически отсутствовала;
-
URL не отражали тематическую иерархию.
Метрики на старте:
-
органический трафик: 184 000 визитов/мес.
-
страницы в ТОП-3: 11,2%
-
средний CTR: 3,7%
-
конверсия в заявку: 1,05%
-
заявки из SEO: 1 932/мес.
-
средний чек услуги: 52 000 ₽
-
выручка из SEO: ≈100,4 млн ₽/год (8,37 млн ₽/мес.)
-
стоимость лида: 3 900 ₽
Контент ранжировался, однако AI-поиск редко использовал сайт как источник ответов. Алгоритм не распознавал целостную экспертную область.
Этап 1. Пересборка таксономии и тематических кластеров
Вместо создания новых материалов команда провела архитектурный аудит.
610 страниц распределили по смысловым кластерам:
-
9 ключевых направлений услуг;
-
43 подтематических группы;
-
выделены hub-страницы (центры тем);
-
устранены дубли тематик.
Каждая статья получила четкую роль:
-
объясняющая;
-
сравнительная;
-
практическая;
-
коммерческая.
Результат через 2 месяца:
-
глубина просмотра выросла с 1,8 до 3,1 страниц;
-
время взаимодействия увеличилось на +39%;
-
доля внутренних переходов выросла на +62%.
Алгоритм начал фиксировать устойчивые тематические связи.
Этап 2. Структурная перелинковка как смысловой сигнал
Перелинковку перестроили по принципу сущностей, а не анкоров.
Изменения:
-
каждая статья ссылалась на родительскую тему;
-
внедрены связи между смежными услугами;
-
добавлены переходы между этапами пользовательского намерения;
-
устранены изолированные страницы.
Среднее количество релевантных внутренних ссылок:
-
было: 3–4
-
стало: 14–18
Через 10 недель:
-
индексируемые тематические связи выросли на +210%;
-
число запросов в ТОП-10 увеличилось на +74%.
Этап 3. Внедрение schema-разметки и entity-моделирования
Добавлена структурированная разметка:
-
Service;
-
Organization;
-
FAQ;
-
Article;
-
BreadcrumbList.
Алгоритм получил формальное описание сущностей:
-
какие услуги оказывает компания;
-
кто автор экспертных материалов;
-
как темы связаны между собой.
Это снизило неоднозначность интерпретации домена.
Через 3 месяца:
-
появление расширенных сниппетов выросло на +128%;
-
упоминания сайта в AI-ответах увеличились в 3,6 раза;
-
брендовые запросы выросли на +47%.
Экономический результат через 8 месяцев
|
Показатель |
До |
После |
|
Органический трафик |
184 000 |
296 000 |
|
Конверсия |
1,05% |
2,14% |
|
Заявки |
1 932 |
6 334 |
|
Средний чек |
52 000 ₽ |
52 000 ₽ |
|
Выручка SEO |
8,37 млн ₽/мес. |
32,9 млн ₽/мес. |
|
Стоимость лида |
3 900 ₽ |
1 180 ₽ |
|
ROI изменений |
— |
≈3 900% |
Инвестиции:
-
архитектурный аудит: 220 000 ₽
-
переработка структуры: 410 000 ₽
-
внедрение schema: 170 000 ₽
Общий бюджет: 800 000 ₽.
Дополнительная ежемесячная выручка после внедрения превысила 24 млн ₽.
Почему архитектура дала такой эффект
LLM-поиск оценивает сайт как граф знаний. После пересборки структуры произошло три ключевых изменения:
-
Алгоритм начал видеть тематическую специализацию домена.
-
Каждая страница получила контекстное подкрепление соседними материалами.
-
Контент стал извлекаемым на уровне сущностей, а не документов.
Фактически сайт перестал быть набором страниц и превратился в связанную экспертную систему.
Экономический вывод
Архитектура контента влияет на доход сильнее, чем увеличение объема публикаций. Причина проста: структурный контекст масштабирует ценность уже созданных материалов.
В рублевом выражении это дает:
-
кратное снижение стоимости привлечения;
-
рост конверсии без изменения продукта;
-
увеличение жизненного цикла контента;
-
усиление присутствия в AI-поиске без дополнительных рекламных затрат.
Когда структура сайта отражает структуру знаний, поисковая система начинает воспринимать ресурс как источник экспертизы.
По мере усложнения поисковых алгоритмов собственники сайтов все чаще сталкиваются с ситуацией, когда вложения в контент и продвижение перестают давать прогнозируемый финансовый результат. Трафик может расти, а продажи — оставаться на прежнем уровне.
Это сигнал, что проблема лежит глубже позиций: поисковые системы не считывают бизнес как целостную экспертную среду. Предприниматели начинают искать не исполнителей отдельных задач, а команды, способные пересобрать стратегию присутствия в поиске на уровне структуры и смысла. Поэтому многие компании обращаются к федеральным агентствам, таким как РОСТСАЙТ, рассчитывая перевести SEO-продвижение сайта из статьи расходов в управляемый канал привлечения клиентов и роста дохода.

Фото из библиотеки без авторского обременения